


RAG — технология, которая помогает языковым моделям давать более точные ответы. Это помогает создавать чат‑ботов, которые заменяют реальных сотрудников, писать статьи с последними цифрами и фактами, анализировать документы без ошибок из‑за устаревших знаний. В статье разбираемся, что такое RAG простыми словами и где применяют такой инструмент. Своим опытом с нами поделился эксперт по автоматизации на базе ИИ, основатель OkoCRM Александр Завьялов.

Если некогда читать весь материал
Что такое RAG — технология, которая позволяет LLM давать более точные ответы. LLM опирается только на ту информацию, на которой её обучали. Эти данные со временем устаревают. Ещё в них может не быть информации по какому‑то узкому запросу. Из‑за этого модель иногда ошибается, фантазирует или даёт неполный ответ.
Retrieval‑Augmented Generation решает эту проблему. Перед тем как сгенерировать ответ, система сначала ищет свежие и релевантные данные в источниках: базе знаний, отчётах, документах.
Вот пример — в OkoCRM есть ИИ-агенты. Они могут обрабатывать запросы пользователей, но для этого в настройках ИИ нужно указать не только сценарии работы инструмента, но и добавить базу знаний. Именно на неё будет опираться ИИ в работе с клиентами.
Допустим, чтобы ИИ-агент мог рассказывать о ценах и скидках, записывать на пробное занятие, нужно добавить в базу знаний:
- стоимость услуг
- варианты скидок и когда о них нужно упоминать
- условия, когда нужно записать на пробное занятие
Именно для такой персонализации и нужна Retrieval‑Augmented Generation.
Ключевые этапы Retrieval‑Augmented Generation:
- Индексация. На этом этапе важно подготовить данные для дальнейшего использования
- Извлечение или поиск. Запрос пользователя преобразуется в вектор, алгоритм вычисляет метрику сходства между вектором запроса и векторами всех фрагментов в базе. Проще говоря, она оценивает, насколько каждый фрагмент близок по смыслу к вопросу пользователя
- Контекстуализация. Алгоритм объединяет найденные релевантные фрагменты с исходным запросом пользователя. Получается единый блок данных — своего рода инструкция или промпт для языковой модели
- Генерация. LLM переходит к формированию ответа. Она анализирует контекст и на его основе генерирует финальный текст. LLM учитывает базовые знания, полученные при обучении, и опирается на информацию из фрагментов. Это помогает выстраивать логичный, связный и понятный ответ
- Проверка. Иногда перед тем как показать ответ пользователю, AI может провести дополнительную проверку. На этом этапе алгоритм оценивает, насколько ответ соответствует запросу
Зачем Retrieval‑Augmented Generation нужна компаниям:
- Помогает обслуживать клиентов: делится инструкциями, отвечает на вопросы, решает простые проблемы
- Позволяет организовать обучение команды: рассказывает о правилах компании, делится инструкциями к сервисам и регламентами
- Персонализирует предложения: умеет подбирать подходящие товары или услуги, опираясь на данные о клиентах
- Анализирует данные: находит закономерности, составляет отчёты
- Создаёт контент и генерирует тексты со свежей информацией, фактами, цифрами
Что такое RAG и LLM
Определение RAG
Retrieval‑Augmented Generation — технология, которая позволяет LLM давать оптимальные ответы. LLM опирается только на ту информацию, на которой её обучали. Эти данные со временем устаревают. Ещё в них может не быть информации по какому‑то узкому запросу. Из‑за этого модель иногда ошибается, фантазирует или даёт неполный ответ.
Retrieval‑Augmented Generation решает эту проблему. Перед тем как сгенерировать ответ, модель сначала ищет свежие и релевантные данные в источниках: базе знаний, отчётах, документах.
Определение LLM
LLM — большая языковая модель — тип программы, которая умеет работать с текстом: понимать его, анализировать и создавать новые тексты, похожие на те, что пишут люди.
Основа LLM — сложные алгоритмы машинного обучения. Прежде чем начать работать с запросами пользователей, модель долго учится на больших объёмах текстовых данных: книгах, статьях, научных работах, документах, статьях из интернета. Языковые модели учатся на миллионах слов и текстов.
Вот пример — в OkoCRM есть ИИ-агенты. Они могут обрабатывать запросы пользователей, но для этого в настройках ИИ нужно указать не только сценарии работы инструмента, но и добавить базу знаний. Именно на неё будет опираться ИИ в работе с клиентами.
Допустим, чтобы ИИ-агент мог рассказывать о ценах и скидках, записывать на пробное занятие, нужно добавить в базу знаний:
- стоимость услуг
- варианты скидок и когда о них нужно упоминать
- условия, когда нужно записать на пробное занятие
Именно для такой персонализации и нужен механизм Retrieval‑Augmented Generation↓
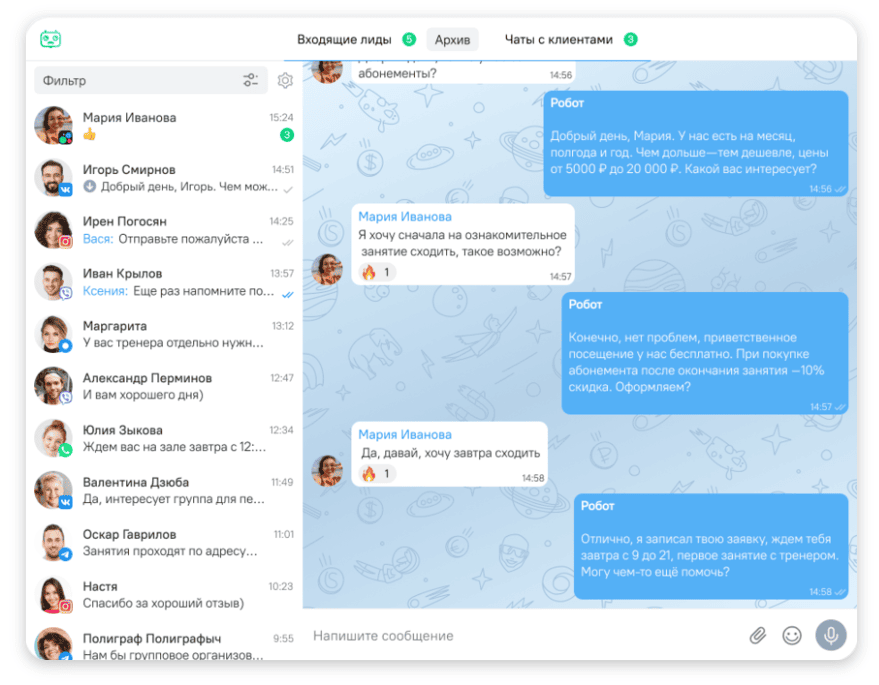
Вот пример того, как работает RAG в OkoCRM — помогает агентам не выдумывать информацию, а брать её из базы знаний компании.

Как работает RAG
Базовый процесс RAG
Шаг 1. Получение запроса. Всё начинается с вопроса от пользователя. Например, он может спросить: «Расскажи, какие инструменты появились в вашем продукте, в CRM, в 2025–2026 годах».
Шаг 2. Поиск релевантных данных. Модель ищет информацию по теме запроса, обращаясь к базе данных. ИИ анализирует запрос и подбирает материалы, которые максимально точно отвечают на поставленный вопрос.
Шаг 3. Извлечение и отбор сведений. Из найденных материалов модель выбирает самые подходящие отрывки. Она оценивает, насколько каждый фрагмент соответствует запросу.
Например, если в базе данных есть раздел «Обновления продукта», ИИ вытащит информацию оттуда и выдаст ответ именно о тех инструментах, которые появились в 2025 и 2026 году.
Шаг 4. Передача данных языковой модели. Отобранные фрагменты алгоритм передаёт большой языковой модели. Теперь у модели есть не только те знания, что были заложены при обучении, но и свежая информация, подобранная по конкретному вопросу.
Шаг 5. Создание ответа. LLM анализирует полученные данные и генерирует структурированный ответ. Пользователь получает развёрнутый и актуальный ответ.
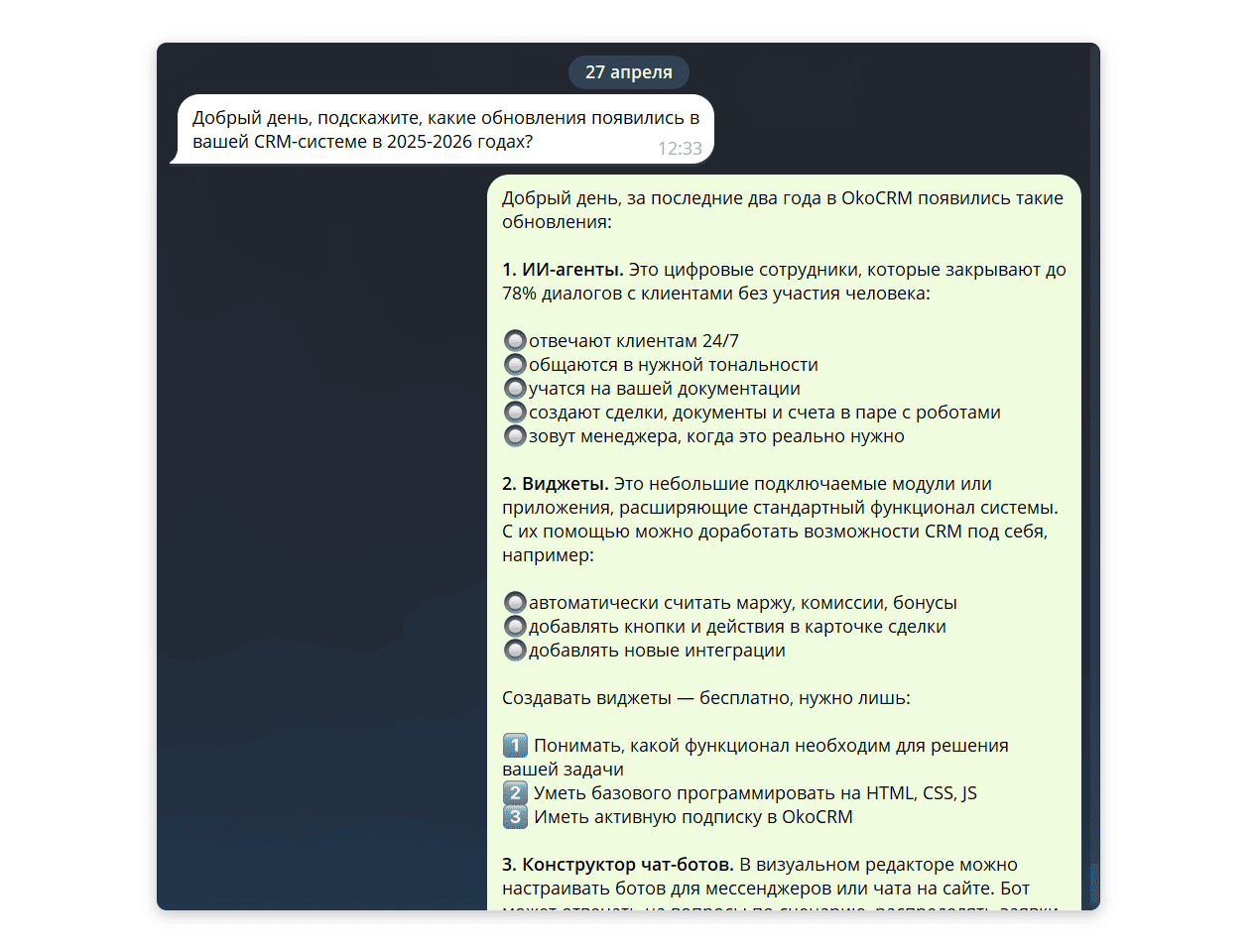
Такой ответ можно получить только благодаря связке РАГ и LLM.
Ключевые этапы RAG
1. Индексация. На этом этапе важно подготовить данные для дальнейшего использования. Процесс состоит из двух важных операций:
- Сегментация. Информацию разбивают на небольшие фрагменты — например, на абзацы или логические блоки. Так системе будет проще потом найти именно тот кусок данных, который нужен для запроса. Такой процесс также называют чанкированием
- Векторизация. Каждый фрагмент преобразуют в числовой вектор — эмбеддинг. Благодаря этому ИИ может сравнивать фрагменты между собой и с пользовательским запросом по смыслу
2. Извлечение или поиск. Когда пользователь пишет запрос, инструмент начинает поиск подходящих сведений в подготовленной базе. Алгоритм трансформирует запрос в вектор, затем определяет сходство между вектором запроса и векторами всех сегментов в базе. Проще говоря, он оценивает, насколько каждый фрагмент совпадает по смыслу с запросом пользователя.
3. Контекстуализация. Алгоритм объединяет найденные соответствующие фрагменты с запросом. Получается единый блок данных — своего рода инструкция или промпт для языковой модели.
4. Генерация. LLM переходит к формированию ответа. Она анализирует контекст и на его основе генерирует финальный текст. LLM учитывает базовые знания, полученные при обучении, и опирается на информацию из фрагментов. Это помогает выстраивать логичный, связный и понятный ответ.
5. Проверка. Иногда перед тем как показать ответ пользователю, AI может провести дополнительную проверку. На этом этапе алгоритм оценивает, насколько ответ соответствует запросу:
- проверяет точность информации
- анализирует, нет ли «галлюцинаций» — выдуманных фактов, которых нет в исходных данных
- иногда добавляет ссылки на источники, использованные при подготовке ответа
Архитектура и компоненты RAG
Ниже — основные элементы архитектуры.
✅ Ретривер. Это модуль поиска. Когда пользователь задаёт вопрос, ретривер ищет в базе данных фрагменты, которые помогут на него ответить. Он сопоставляет запрос с имеющимися данными и отбирает самые релевантные фрагменты.
✅ Генератор. Это LLM, которая формирует итоговый ответ. Она получает от ретривера исходный запрос и найденные фрагменты. Затем анализирует информацию, объединяет свои базовые знания с новыми данными, составляет понятный текст.
✅ Векторная база данных. Это хранилище информации, подготовленной особым образом для точного поиска. В отличие от обычного текстового поиска, здесь данные представлены в виде векторов. Благодаря векторизации AI может искать не просто совпадения слов, а фрагменты, близкие по содержанию к запросу.
✅ Модель эмбеддингов. Этот компонент преобразует текст в векторы. При подготовке базы данных он превращает фрагменты текста в векторы, а при обработке запроса преобразует вопрос пользователя в вектор, чтобы сравнить его с векторами из базы. Это позволяет точнее сопоставлять запрос и данные между собой.
✅ Система поиска и формирования контента. Это связующее звено между поиском и генерацией. Алгоритм:
- принимает запрос пользователя
- запускает процесс поиска через ретривер
- собирает найденные фрагменты и объединяет их с запросом в единый блок данных
- передаёт этот блок генератору для создания ответа
✅ Фреймворки. Такие инструменты ещё называют оркестраторами. Они соединяют все этапы, задают порядок их работы. Примеры таких фреймворков — LangChain, LlamaIndex и другие.
Преимущества и ограничения RAG
Преимущества RAG
Ниже — зачем Retrieval‑Augmented Generation нужна компаниям.
Помогает генерировать более точные ответы. AI опирается не только на данные, заложенные при обучении модели, но и ищет актуальную информацию в базе данных или документах. Поэтому АИ может выдавать данных о событиях, которые произошли совсем недавно, или рассказывать клиентам о компании.
Инструмент можно настроить. Retrieval‑Augmented Generation можно адаптировать под разные задачи и базы данных. Например, настроить инструмент на поиск информации только в корпоративных документах, научных публикациях или новостных статьях. Это делает механизм полезным в разных сферах: техподдержке или продажах, научных исследованиях или чат-ботах.
Помогает сделать работу прозрачной. Обычно ИИ может показать, откуда брал данные для ответа: добавить ссылки на источники или процитировать фрагменты. Пользователь может проверить информацию самостоятельно
Подходит для разных задач и ниш. Retrieval‑Augmented Generation используют для разных задач. АИ отвечает на вопросы, составляет инструкции, анализирует документы. Механизм хорошо работает и со специализированными темами, и с общими запросами.

Ограничения и риски
Зависит от качества базы данных. Если в источниках есть ошибки, устаревшие или противоречивые сведения, ИИ будет выдавать неверную информацию. Алгоритмы просто используют то, что нашли.
Сложно настраивать. Чтобы Retrieval‑Augmented Generation работала эффективно, нужно правильно организовать векторную базу данных, подобрать модель эмбеддингов и настроить модуль поиска.
Технические требования. Для работы Retrieval‑Augmented Generation нужна инфраструктура: серверы, мощности для обработки запросов, доступ к языковым моделям. Это может быть сложно и дорого для небольших компаний.
Парадигмы RAG
Базовый подход (Naive RAG)
Базовый подход к Retrieval‑Augmented Generation, который называют Naive RAG — самая простая и распространённая версия технологии. Её функционал простой: сначала алгоритм находит данные, потом генерирует ответ. Для этого нужно пройти три базовых этапа, о которых мы говорили раньше: индексацию, извлечение и генерацию.
Этот подход можно выбирать в ситуациях, когда:
- нужно быстро запустить AI с поддержкой актуальных данных
- запросы простые, информационные
- база данных уже структурирована и в ней достаточно релевантной информации
- нет необходимости в тонкой настройке генерации под разные стили, запросы или сегменты аудитории
Advanced RAG
Advanced — более развитая концепция по сравнению с базовой. Чтобы сделать процесс поиска информации точнее, используют дополнительные техники. Разберём два ключевых этапа этой парадигмы.
Этап предварительной обработки. Он идёт до старта поиска данных. Его задача — лучше понять запрос пользователя и подготовить его для эффективного поиска.
Например, используют технику оптимизации «Скользящее окно», разбивая информацию на сегменты определённого размера. Благодаря предварительной обработке инструмент ищет не просто совпадения слов, а информацию, которая действительно отвечает на вопрос пользователя.
Этап постобработки. Этот этап наступает после того, как алгоритм нашёл данные. Его цель — улучшить качество ответа перед тем, как передать его LLM. К примеру, можно использовать функцию переранжирование, чтобы размещать самые актуальные фрагменты данных в начале ответа.
Modular RAG
Modular — самая гибкая версия. В этом случае добавляются отдельные модули и паттерны взаимодействия между ними. Допустим, модуль поиска отвечает за поиск информации во внешних источниках и может обращаться к разным базам данных.
Модуль RAG‑Fusion используют для улучшения поиска за счёт множественных запросов. Паттерн Recite-Read извлекает факты из текста, чтобы с их помощью найти ещё больше данных. Например, если пользователь спрашивает: «Как снизить энергопотребление в офисе зимой», RAG‑Fusion может разбить запрос на части:
- способы экономии электричества в офисе
- теплоизоляция офисных помещений
- эффективные обогреватели для офисов
Алгоритм найдёт информацию по каждому направлению, ответ получится более конкретным.
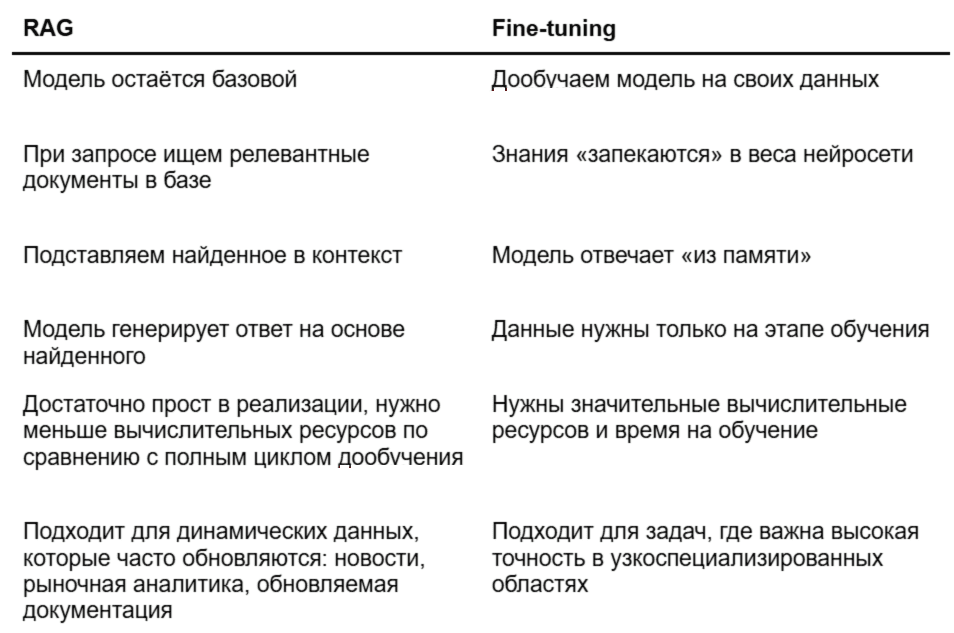
Сравнение RAG и файнтюнинга
Fine-tuning — дообучение LLM под специфические решения. Допустим, LLM нужна для генерации маркетинговых материалов. Нейросеть может написать текст для рассылки, баннеров или пушей, но они будут плюс-минус стандартными. Чтобы ИИ смог выдать более подходящий текст, можно дообучить LLM.
Отличия подходов сравнили в таблице ↓
Практические кейсы и применение RAG
Вопросно-ответные системы
Вопросно‑ответные системы — одна из самых распространённых сфер применения Retrieval‑Augmented Generation. Она позволяет пользователям получать ответы на вопросы, опираясь не только на данные, на которых происходило обучение, но и на свежую информацию из внешних источников. Ниже перечислим основные сферы применения RAG.
Техподдержка. Компании внедряют Retrieval‑Augmented Generation в ИИ-агентов службы поддержки. Для помощи клиентам алгоритм находит в базе знаний нужные инструкции, описания решений типовых проблем. Клиенты получают ответы быстро, не ждут оператора. Нагрузка на специалистов техподдержки снижается, они решают более сложные проблемы пользователей.
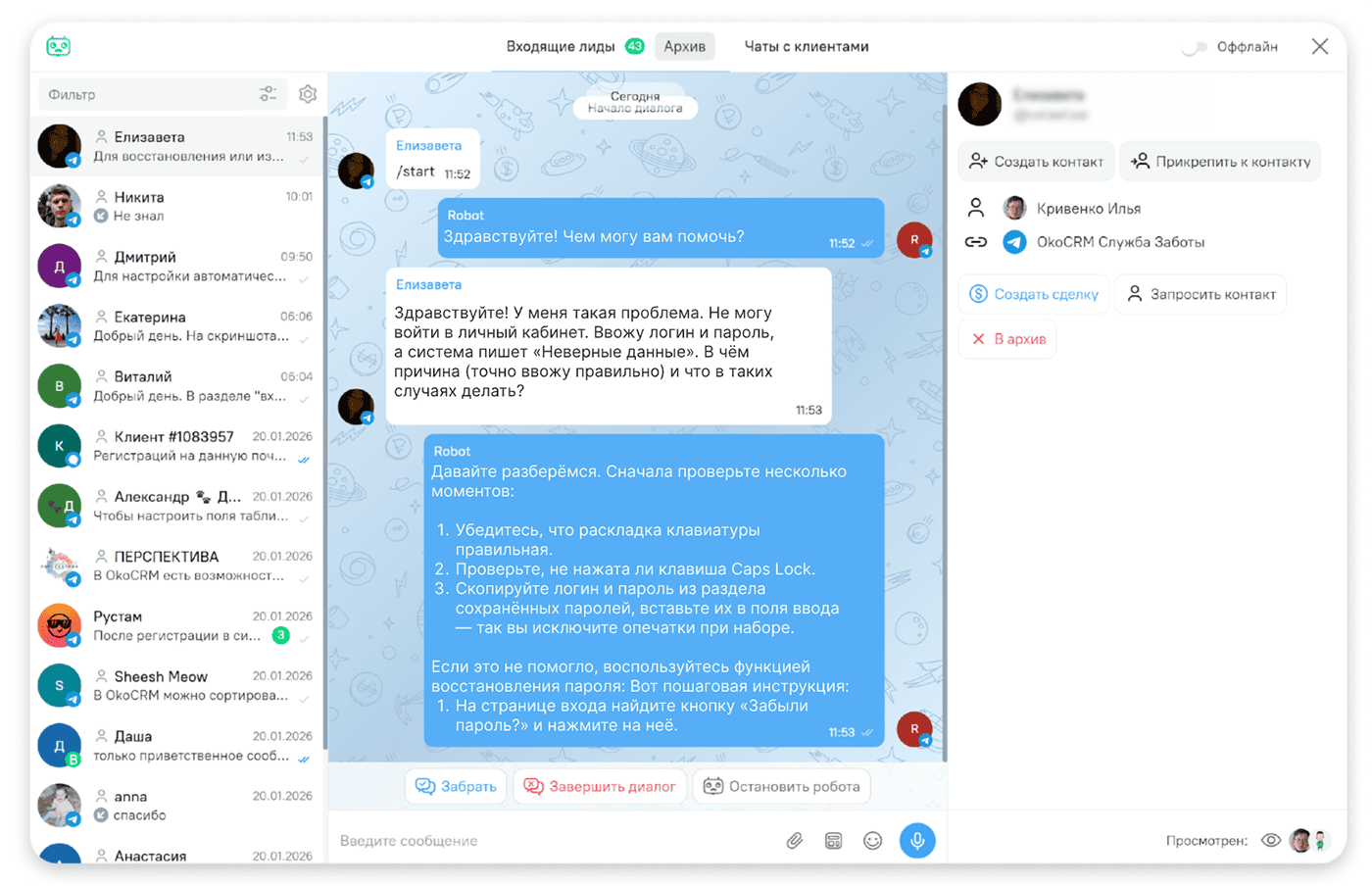
Например, ИИ-агента OkoCRM можно сразу использовать в техподдержке — LLM уже обучена, а в настройках можно подгрузить свою базу данных. Так работает ragging models.
Консультации и продажи. Искусственный интеллект может работать вместо консультанта. Пользователь уточняет, есть ли в компании услуга онлайн-обучения, АИ отвечает на вопрос, опираясь на информацию из базы данных. Дальше человек интересуется ценами, условиями оплаты, гарантиями, ИИ находит нужные данные и отправляет в чат.
Обучение сотрудников. Retrieval‑Augmented Generation используют для адаптации и обучения новых сотрудников. АИ отвечает на вопросы новичков о рабочих процессах, делится правилами, помогает осваивать инструменты компании. Новые сотрудники быстрее вливаются в работу, а наставники меньше времени тратят на объяснения.
Помощь сотрудникам. AI можно использовать как умный справочник. Чат-бот будет отвечать на типовые вопросы. Например, как оформить заявку клиента или что делать, если тот требует возврат денег.

Персонализированные рекомендации
Retrieval‑Augmented Generation помогает делать персонализированные рекомендации. Она учитывает данные о пользователе, контекст взаимодействия с ним, его предпочтения, чтобы предложить актуальный товар или услугу.
Например, покупатель часто выбирает спортивную одежду. RAG анализирует его предпочтения: размер, бренды, ценовой диапазон. Она подбирает актуальные модели и добавляет их в рассылку. За счёт того, что люди получают интересующие подборки товаров, конверсия рассылки растёт.
Контентная генерация
Retrieval‑Augmented Generation используют и для создания контента. Обычные LLM опираются только на данные, на которых их обучали. RAG перед созданием текста использует информацию из внешних источников, поэтому материал становится более подробным, в него можно добавить факты или свежие исследования.
Что можно сгенерировать:
- Статьи и обзоры. Например, обзор новинок смартфонов с реальными характеристиками и ценами
- Инструкции и руководства. Пошаговые инструкции по настройке оборудования или использованию ПО с учётом последних обновлений
- Маркетинговые материалы. Тексты для рекламы, лендингов, email‑рассылок, соцсетей
- Образовательные материалы. Учебные модули, тесты, конспекты лекций
- Новостные дайджесты. Краткие сводки событий по выбранной теме
- Технические документы. Спецификации, описания API, документацию к продуктам
Специализированные чат-боты
С помощью Retrieval‑Augmented Generation компании могут улучшить LLM, заточить инструмент под свою нишу. Приведём примеры нескольких сфер, в которых это особенно актуально.
Юридические ассистенты. Такие чат‑боты помогают юристам быстро находить нужные законы и разъяснения для клиентов. Или помогают людям получить консультацию. Для этого алгоритмы обращаются к базам законов, судебных решений и комментариев экспертов. В юридических документах каждое слово имеет значение и может повлиять на трактовку всего текста.
Медицинские ассистенты. Такие чат‑боты используют клинические рекомендации, исследования, инструкции к препаратам и официальные протоколы лечения. Они помогают врачам быстро находить информацию. Или могут помочь людям быстрее находить нужную информацию.
Что могут делать медицинские ассистенты с помощью Retrieval‑Augmented Generation:
- искать описания симптомов и факторов риска
- уточнять схемы приёма препаратов и возможные взаимодействия лекарств
- находить свежие исследования по конкретным заболеваниям
- объяснять медицинские термины простым языком
Аналитические инструменты. Аналитические чат‑боты чаще всего используют как вспомогательный элемент для сотрудников. ИИ помогает подготавливать отчёты, анализирует данные и находит закономерности, объясняет результаты понятным языком.
Как бизнес может использовать RAG
Retrieval‑Augmented Generation помогает бизнесу решать множество задач:
- Обслуживать клиентов: делиться инструкциями, отвечать на вопросы, решать простые проблемы
- Организовать обучение команды: рассказывать о правилах компании, делиться инструкциями к сервисам и регламентами
- Персонализировать предложения: подбирать подходящие товары или услуги, опираясь на данные о клиентах
- Анализировать данные: находить закономерности, составлять отчёты
- Создавать контент и генерировать тексты со свежей информацией, фактами, цифрами
Чек-лист для внедрения RAG
- Определите цель внедрения. Подумайте, какую задачу должен решить инструмент
- Подготовьте данные для извлечения: отчёты, документы, базу знаний. Реализация RAG начинается с подготовки базы данных, к которой будет обращаться механизм
- Выберите технологическую базу: LLM, векторную базу данных, фреймворк для управления процессом, интерфейс для взаимодействия с пользователями, например, чат‑бот в Telegram или CRM-систему
- Настройте процесс извлечения и генерации. Проработайте логику работы работы инструмента: как будет происходить поиск данных, какие фильтры применять для отсева неактуальной информации, как объединять фрагменты из разных источников
- Запустите MVP — минимально жизнеспособный продукт. Разверните прототип на ограниченном наборе данных — например, 100–500 документов
- Протестируйте и доработайте механизм. Дайте доступ к MVP небольшой группе пользователей — сотрудникам или лояльным клиентам. Соберите обратную связь
- Внедрите инструмент. После успешного тестирования расширьте базу данных и подключите дополнительные сценарии
- Оцените результаты. Через 1–3 месяца после запуска проанализируйте эффект. Сравните показатели до и после внедрения: скорость обработки запросов, количество обращений к операторам, NPS
- Запланируйте развитие. Retrieval‑Augmented Generation можно улучшать и расширять. Например, подумайте о добавлении новых модулей
Когда RAG не подходит
Retrieval‑Augmented Generation — не универсальный инструмент. Например, он не подходит для задач в узкоспециализированных областях, для которых важна высокая точность.
В некоторых сферах ошибка даже в одном факте может привести к серьёзным последствиям. Например, ИИ в медицине при постановке диагноза может ошибаться, так как опирается на найденные фрагменты данных. Если в источнике есть неточность, она может попасть в итоговый ответ.
Для рутинных операций Retrieval‑Augmented Generation не нужна, для стандартных задач достаточно обычной LLM и хорошо написанного промпта. Например, для генерации текста бывает достаточно обычной нейросети. А вот если нужен какой-то специализированный контент, тогда есть смысл использовать Retrieval‑Augmented Generation.
Retrieval‑Augmented Generation ориентирована на поиск и синтез существующей информации. Он плохо подходит для:
- создания оригинальных художественных текстов
- генерации идей в чистом виде
- разработки принципиально новых дизайнов или архитектурных решений
Итоги и дальнейшие шаги после внедрения RAG
После того как Retrieval‑Augmented Generation запущена, необходимо регулярно оценивать её работу и вносить улучшения. Ниже — что именно нужно делать.
Оценивать качество работы инструмента. Важно понимать, насколько хорошо система справляется с задачами. Для этого нужно:
- отслеживать точность ответов
- проверять актуальность информации
- анализировать полноту ответов
- оценивать скорость работы
- собирать обратную связь от пользователей
- считать ключевые метрики: процент успешно решённых запросов, число обращений к операторам после внедрения инструмента, NPS
Настраивать компоненты инструмента. На основе собранных данных улучшайте отдельные части Retrieval‑Augmented Generation: ретривер, генератор, источники данных.
Дорабатывать инструмент итерациями. Улучшения оптимально проводить поэтапно. Например, выбрать одну проблему или направление для улучшения, вносить изменения в соответствующий компонент.

FAQ: часто задаваемые вопросы о RAG
Что такое RAG
Retrieval‑Augmented Generation, или «генерация с дополненным извлечением» — технология, которая помогает языковым моделям давать оптимальные ответы.
Чем RAG отличается от обычной языковой модели
Языковая модель опирается только на те данные, на которых её обучали. Эти данные со временем устаревают. Ещё в них может не быть информации по какому‑то узкому запросу. Из‑за этого модель иногда ошибается, фантазирует или даёт неполный ответ. Retrieval‑Augmented Generation решает эту проблему. Перед тем как сгенерировать ответ, инструмент сначала ищет свежие и релевантные данные в источниках: базе знаний, отчётах, документах.
Какие задачи решает RAG
Механизм подходит для:
- ответов на вопросы клиентов в чат‑ботах
- консультаций покупателей
- создания статей, отчётов и инструкций с актуальными данными
- создания персонализированных рекомендаций
- генерации контента
Нужно ли постоянно обновлять базу данных для RAG
Да. Успешная реализация Retrieval‑Augmented Generation напрямую зависит от качества информации в источниках. Почему это важно? Если данные устарели, ответы могут быть неточными. Базу нужно регулярно пополнять и удалять неактуальную информацию.



